Hadoop 2.0 – ein großer Schritt zum Big-Data-Betriebssystem

Die Apache Foundation hat Hadoop 2.0 vorgestellt. Mit zahlreichen neuen Funktionen wird die Big-Data-Technologie stabiler und auch einfacher zu nutzen.
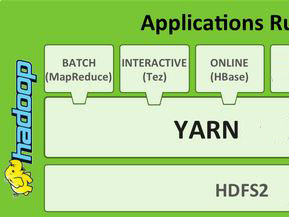 Eine der wichtigsten Komponenten in Hadoop 2.0 ist YARN. YARN wird häufig auch als MapReduce 2.0 oder MRv2 bezeichnet. Gegenüber MapReduce 1.0 hat jedoch YARN den Vorteil, dass Das Management der Engine aus dem eigentlichen Algorithmus ausgeklammert ist. Das bedeutet auch, dass Anwender denMapReduce-Algorithmus wie ein Plug-in austauschen und stattdessen etwa ein interaktives Verfahren verwenden können.
Eine der wichtigsten Komponenten in Hadoop 2.0 ist YARN. YARN wird häufig auch als MapReduce 2.0 oder MRv2 bezeichnet. Gegenüber MapReduce 1.0 hat jedoch YARN den Vorteil, dass Das Management der Engine aus dem eigentlichen Algorithmus ausgeklammert ist. Das bedeutet auch, dass Anwender denMapReduce-Algorithmus wie ein Plug-in austauschen und stattdessen etwa ein interaktives Verfahren verwenden können.
Dies gilt als Meilenstein bei der Entwicklung von Hadoop von einem einfachen Werkzeug hin zu einem kompletten Betriebssystem für Big Data. YARN steht für “Yet Another Resource Negotiator”, ist also ein selbstreferenzielles Akronym. Zwar gibt es bereits auf Apache Hadoop aufsetzende Distributionen mit YARN, etwa Cloudera CDH, sie basieren aber auf einer Hadoop-Version, die Apache noch als Preview eingestuft hat.
“Hadoop 2 markiert eine bedeutende Weiterentwicklung des Open-Source-Projekts, die leidenschaftliche Entwickler der Apache-Gemeinschaft gemeinsam erstellt haben. Ihr Ziel war es vor allem, die Datenplattform einfacher nutzbar und stabiler zu machen”, so der Release Manager Arun C. Murphy.
Neu in Hadoop 2.0 sind Hochverfügbarkeit für die Apache-Version von HDFS, also das Hadoop Distributed File System, Unterstützung von Microsoft Windows, Data-Snapshots in sowie NFS-v3-Zugang zu HDFS. Föderation von HDFS ermöglicht deutlich bessere Skalierbarkeit als mit Apache Hadoop 1.x. Gleichzeitig besteht Binärkompatibilität zu MapReduce-Anwendungen, die für Apache Hadoop 1.x geschrieben wurden.
Parallel hat das Projekt Apache Hive eine neue Version (0.12.0) vorgelegt, die zu Hadoop 2.0 kompatibel ist. Hive ermöglicht SQL-Abfragen von Hadoop-Daten. Es basiert derzeit auf den MapReduce-Algorithmus. Mit Apache Tez und Hortonworks Stinger gibt es aber schon Entwicklungen, um Hives SQL-Anfragen über YARN abzuwickeln und MapReduce zu umgehen, sodass auch Hive mit alternativen Algorithmen zurechtkommt.
[mit Material von Florian Kalenda, ZDNet.de]
Tipp: Wie gut kennen Sie sich mit Open-Source aus? Überprüfen Sie Ihr Wissen – mit 15 Fragen auf silicon.de.




