10 Lehren aus 10 Jahren Amazon Web Services
Cloud und Cloud Computing sind heute fester Bestandteil jeder Diskussion über die Firmen-IT. Vor zehn Jahren, als AWS mit dem Betrieb von Amazon S3 begann, war das noch anders, Im Gastbeitrag für silicon.de schildert CTO Werner Vogels die zehn wichtigsten Erkenntnisse aus zehn Jahren Cloud-Betrieb.
AWS betrat mit dem Launch von Amazon S3 am 14. März 2006 den Markt. Seitdem haben wir viel über Bauen und Betreiben von sicheren, verlässlichen und skalierbaren Services gelernt, die mit vorhersehbarer Leistung zu niedrigen Kosten angeboten werden. Und Erfahrung ist durch nichts zu überbieten.

Mit über einer Million aktiver Kunden pro Monat, die wiederum Millionen von eigenen Kunden haben, lernen wir täglich dazu. Das sind die besten Voraussetzungen, um den Service für unsere Kunden stetig zu verbessern. Aus dieser Erfahrung heraus habe sich einige Aspekte ergeben, die hoffentlich auch für Sie von Nutzen sind und die ich im Folgenden einmal zusammengestellt habe.
1. Evolutionsfähige Systeme bauen
Wir entwickeln unsere Software fortlaufend weiter. Uns war bewusst, dass sie nach einem Jahr nicht mehr unseren Anforderungen entspricht. Die Erwartung war, dass wir mit jedem oder jedem zweiten großen Auftrag die Architektur überdenken und überarbeiten müssten.
Wir könnten unseren Betrieb schlecht einstellen, nur um Wartungsarbeiten durchzuführen oder Services zu erweitern. Viele Unternehmen nehmen unsere Dienste rund um die Uhr in Anspruch. Es musste möglich sein, neue Software hinzuzufügen, ohne den Service “offline” zu nehmen.
Einer unserer Engineers, Marvin Theimer, hat dafür ein treffendes Bild gefunden: Wir sind als einmotorige Cessna gestartet, aber im Lauf der Zeit haben wir uns im Flug zur 737 weiterentwickelt, dann zu einer Gruppe von Jumbo-Jets. Heute sind wir ein großes Geschwader von Airbus A380. Dabei tanken wir dauernd in der Luft auf und unsere Kunden steigen von einem Flugzeug ins nächste um, ohne dass sie das überhaupt wahrnehmen.
2. Auf das Unerwartete vorbereitet sein
Ausfälle kommen überall vor und zwar unabhängig von der Qualität der Hardware: Vom Router bis zur Festplatte, vom Betriebssystem bis hin zu Speichermodulen, die TCP-Pakete beschädigen. Das Spektrum reicht von reparablen Aussetzern bis hin zu endgültigen Schäden.

Das wird in Zusammenhang mit unseren Skaleneffekten noch entscheidender: S3 verarbeitet beispielsweise Trillionen von Speichertransaktionen. Bei dieser Größenordnung wird auch der unwahrscheinlichste Fehler eintreten. Viele dieser Szenarien lassen sich vorausberechnen. Als wir S3 entwickelt und aufgebaut haben, waren andere dagegen absolut unvorhersehbar.
Unsere Systeme mussten Fehler als normales Ereignis einbeziehen – selbst wir wussten nicht, wie die Fehler genau aussehen würden. Die Systeme müssen selbst im äußersten Problemfall weiterlaufen. Bestimmte Bereiche müssen verwaltet werden können, ohne gleich das gesamte System heruntergefahren werden muss. Wir haben gelernt, den Explosionsradius einzelner Schadensereignisse so gut im Griff zu haben, dass das Gesamtsystem immer einsatzfähig bleibt.
3. Grundfunktionen, keine Frameworks
Wir legen unsere Kunden nicht darauf fest, wie sie unsere Services nutzen. Nachdem sie die beengende, alte Welt der IT-Hardware und Rechenzentren verlassen hatten, entwickelten sie neue Nutzungsmuster. Wir mussten daher so agil wie möglich sein, um den Anforderungen unserer Kunden zu entsprechen.
Unsere zentrale Herangehensweise: Wir stellten für unsere Kunden einige Grundfunktionen und Werkzeuge zusammen. So konnten sie selbst wählen, wie sie die AWS Cloud nutzen wollen, statt in ein Framework gezwungen zu sein, das alles bis ins letzte Detail vorgibt. Dieser Ansatz hat unsere Kunden so erfolgreich gemacht, dass sogar spätere Generationen der AWS Services auf genau den einfachen Diensten aufbauen, an die sich unsere Kunden gewöhnt haben.
Eine weitere, interessante Erkenntnis: Es ist schwer vorherzusagen, welche Prioritäten Kunden setzen, bevor sie einen Service verwenden und anfangen, damit zu arbeiten. Deshalb stellen wir neue Services oft nur mit minimalem Funktionsumfang bereit. Unsere Kunden dürfen dann mitbestimmen, welche weiteren neuen Funktionen dazukommen sollen.
4. Automation ist entscheidend
Es ist ein gravierender Unterschied, Software für den Betrieb zu entwickeln, oder Software zu entwickeln, die an Kunden ausgeliefert wird. Systeme in großem Maßstab zu verwalten setzt eine andere Denkweise voraus, damit die Erwartungen der Kunden an Zuverlässigkeit, Leistung und Skalierbarkeit erfüllt werden.

Ein Schlüsselmechanismus dafür ist es, das Management weitestgehend zu automatisieren. Fehleranfällige manuelle Vorgänge entfallen dadurch. Um dahin zu kommen, mussten wir Management-APIs bauen, die die wichtigsten Funktionen unserer Abläufe steuern. AWS hilft den Kunden dabei, das ebenfalls zu tun, indem man Anwendungen mit einer Management-API in die wesentlichen Bestandteile zerlegt und so Automatisierungsregeln festlegt. So ist zuverlässige und kalkulierbare Performance in großem Maßstab sicher. Ein guter Indikator: Es gibt noch viel zu automatisieren, wenn man per SSH auf einen Server oder eine Instanz zugreift.
5. APIs sind für die Ewigkeit
Das hatten wir bereits bei Amazon.com begriffen. Für das Business von AWS, das auf APIs fokussiert ist, gewann diese Erkenntnis noch einmal an Bedeutung. Sobald Kunden angefangen haben, ihre Anwendungen und Systeme mit unseren APIs aufzubauen, können wir diese APIs unmöglich ändern. Das würde die Geschäftstätigkeit unserer Kunden direkt beeinträchtigen. Wir waren uns daher immer dessen bewußt, dass die Entwicklung von APIs eine enorm wichtige Aufgabe ist. Wir haben hier nur eine Chance, es richtig zu machen.
6. Kenne deine Ressourcenauslastung
Wenn man ein Finanzierungsmodell für einen Service aufstellt, um die richtige Preisstruktur zu ermitteln, sollten präzise Daten über die Kosten des Dienstes und über seinen Betrieb vorliegen. Das gilt besonders, wenn er auf großen Volumina und niedrigen Margen basiert. AWS musste sich als Service-Provider über die eigenen Kosten im Klaren sein. Nur so konnten wir unsere Dienste Kunden anbieten und Bereiche identifizieren, in denen wir die Kosten durch effizienteren Betrieb weiter senken konnten. Diese Einsparungen haben wir dann in Form niedrigerer Preise an die Kunden weitergegeben.
Ein Beispiel aus frühen Tagen, als wir noch nicht genau wussten welche Ressourcen für bestimmte Nutzungsmodelle von S3 nötig waren, soll das illustrieren: Wir dachten, dass Speicherplatz und Bandbreite die Ressourcen wären, für die wir Kosten erheben müssten. Nach einer Weile haben wir festgestellt, dass die Zahl der Abfragen mindestens genauso bedeutend ist. Haben Kunden viele sehr kleine Dateien, dann kommt nicht viel Speicherplatz und Bandbreite zusammen, selbst wenn sie Millionen von Abfragen durchführen. Daher haben wir unser Modell angepasst, um die unterschiedliche Ressourcennutzung abzudecken und AWS zu einem nachhaltigen Unterfangen zu machen.
7. Von Anfang an für Sicherheit sorgen
Es sollte immer oberste Priorität sein, die Kunden zu schützen. Für AWS war das immer eine Priorität, sowohl im Hinblick auf den Betrieb als auch in Bezug auf Werkzeuge und Mechanismen. In diesem Bereich werden wir auch immer am meisten investieren.
Ein Ansatz ist uns schnell klar geworden: Um sichere Services aufzubauen, muss Sicherheit von Anfang an integraler Bestandteil des Service-Designs sein. Das Security-Team ist nicht irgendeine Gruppe die Bewertungen vornimmt, nachdem etwas fertig aufgebaut ist. Es muss vom ersten Tag an Partner sein, um sicherzustellen, dass die Sicherheitsvorkehrungen wirklich von Grund auf solide sind. Bei der Sicherheit gibt es keine Kompromisse.
8. Verschlüsselung ist “First-Class Citizen”
Für Kunden ist Verschlüsselung ein grundlegender Mechanismus um sicherzustellen, wer Zugriff auf ihre Daten hat. Vor zehn Jahren waren Verschlüsselungs-Tools und -Services noch schwer zu bedienen. Wir haben erst nach einigen Jahren gelernt, wie wir Verschlüsselung am besten in unsere Services integrieren.
")
Zunächst haben wir in S3 eine serverseitige Verschlüsselung für Compliance Use Cases zur Verfügung gestellt. Beim Versuch, eine Festplatte in unseren Rechenzentren auszulesen, wird der Zugriff auf die Daten verhindert. Aber mit dem Start von Amazon CloudHSM für Hardware-Security Modelle und später mit dem Amazon Key Management Service wurden Kunden in die Lage versetzt, ihre eigenen Keys für die Verschlüsselung zu verwenden. AWS musste ihre Schlüssel also nicht mehr verwalten.
Seit einiger Zeit ist der Support für Verschlüsselung fester Bestandteil der Design-Phase eines jeden neuen Dienstes geworden. Bei Amazon Redshift wird zum Beispiel jeder Datenblock standardmäßig mit einem zufälligen Key verschlüsselt. Diese gesammelten Zufallsschlüssel sind dann wiederum mit einem Master-Key verschlüsselt. Dieser Master-Key kann von den Kunden bereitgestellt werden. Sie stellen damit sicher, dass sie wirklich die einzigen sind, die ihre wichtigen geschäftlichen Daten oder persönlichen Informationen entschlüsseln und darauf zugreifen können.
Verschlüsselung hat für unser Geschäft auch weiterhin hohe Priorität. Wir werden es unseren Kunden künftig einfacher machen, Verschlüsselungstechnologie einzusetzen. So können sie sich und ihre eigenen Kunden noch besser schützen.
9. Die Bedeutung des Netzwerks
AWS unterstützt inzwischen alle möglichen Workloads – von der Transaktionsabwicklung mit hohem Volumen bis hin zur Videotranscodierung in großem Maßstab, von parallelem Hochleistungs-Computing bis hin zu massivem Website-Traffic. Jede dieser Aufgaben stellt eigene Anforderungen an das Netzwerk.
AWS kann Rechenzentren entwerfen und betreiben. Und zwar so, dass wir flexible Netzwerkinfrastrukturen zur Verfügung haben, die sich an die Erfordernisse unserer Kunden anpassen. Ganz egal, wie diese aussehen. Mit der Zeit ist uns klar geworden, dass wir nicht davor zurückschrecken dürfen, unsere eigenen Hardwarelösungen zu entwickeln. Damit stellen wir sicher, dass unsere Kunden ihre Ziele erreichen können. Wir erfüllen so auch unsere eigenen, sehr spezifischen Anforderungen, zum Beispiel, AWS Kunden voneinander im Netzwerk zu isolieren, um das höchste Sicherheitsniveau zu erreichen.
Wir haben uns außerdem der so genannten Virtualisierungsabgabe beim Netzwerkzugriff mit virtuellen Maschinen gewidmet. Der Zugang zum Netzwerk ist eine geteilte Ressource. Kunden stellten daher früher manchmal deutliche Schwankungen im Netzwerk fest. Wir haben deshalb einen negativen Impedanzkonverter (NIC) entwickelt, der Single Root IO-Virtualisierung unterstützt. So konnten wir jeder virtuellen Maschine ihren eigenen Hardware-virtualisierten NIC zuweisen. Dadurch haben wir mehr als halb so große Latenzen realisiert und konnten Latenzschwankungen um den Faktor zehn reduzieren.
10. No Gatekeeper
Das AWS-Team hat im Laufe der Zeit zahlreiche Services und Funktionen bereitgestellt, die zusammen eine umfangreiche Plattform für unsere Kunden bilden. AWS ist allerdings deutlich mehr als nur die Services, die wir selbst entwickelt haben. Es gibt ein vielfältiges Ökosystem an Services, die von unseren Partnern angeboten werden. Sie erweitern die Plattform in viele neue Richtungen.
Unser Partner Stripe zum Beispiel bietet Twilio Bezahldienste an. Twilio wiederum macht mit AWS Telefonie programmierbar. Viele unserer Kunden bauen auch selbst Plattformen auf der Basis von AWS, um spezielle vertikale Bedürfnisse zu befriedigen. Philips etwa setzt so seine Healthsuite Digital Plattform für die Verwaltung von medizinischen Daten auf, Ohpen hat auf AWS eine Plattform für Retail-Banking aufgebaut und Eagle Genomics eine Plattform für die Genomforschung.
Entscheidend dafür ist: Bei der AWS Plattform gibt es keine Gatekeeper, die unseren Partnern vorschreiben, was sie tun können und was nicht. Die “No Gatekeeper”-Politik setzt innovative Prozesse frei und öffnet unerwarteten Erfindungen Tür und Tor. Und die kommen mit Sicherheit.
Ich freue mich darauf, zu sehen was wir in den nächsten zehn Jahren noch alles lernen und was die AWS Kunden erreichen. Und immer daran denken: It is still Day One…
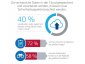
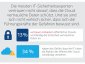
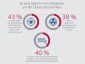
Cloud Security Report von Intel Security