Hortonworks erweitert die Hortonworks Data Plattform (HDP). HDP ist eine YARN-basierte Hadoop-Distribution, die vor allem den Einsatz von Hadoop in Unternehmen vereinfachen soll. HDP 2.5 liefert neue Features für Sicherheit und Governance sowie Erweiterungen für den Betrieb und die Verwaltung von Rechenzentren und natürlich auch neue Möglichkeiten für die Auswertung von Daten. Der Release der neuen Version ist für das dritte Quartal geplant, wie das Unternehmen auf dem beim Hadoop Summit in San Jose erklärt hat.

In der neuen Auflage der Hortonworks Data Platform können über Atlas Metadaten-Tags zur Klassifizierung von Daten vergeben werden. Diese Metadaten kann wiederum Apache Ranger verwenden, um Zugriffsrichtlinien anzuwenden. Atlas lasse sich auch komponentenübergreifend verwenden, denn das Apache-Projekt wurde von der Data-Governance-Initiative zusammen mit Anwendern und Partnern wie Aetna, Target, Merck, Schlumberger, SAS und SAP entwickelt.
Ebenfalls neu ist ein Notebook auf Basis von Apache Zeppelin für Enterprise Spark. Zeppelin unterstützt Data Ingestion, Data Exploration, Visualisierung und bringt zudem auch Collaboration-Features für Daten-Ingenieure. Mit Support für die neueste Version von Apache Ambari sorgt Hortonworks für ein Streamlining. Mit Ambari lassen sich Apache Hadoop-Cluster provisionieren, überwachen und absichern.
Wer über Hadoop in großen Mengen Echtzeit- und Streaming-Daten verarbeiten will, kann dafür künftig auf Storm zurückgreifen. Die Echtzeit-Engine erlaubt es, mehrere Millionen Daten pro Sekunde auf einem Node zu verarbeiten und eignet sich für Real-Time Analytics, Machine Learning und das Monitoring von Event-Prozessen.
Mit der NoSQL-Datenbank Apache HBase und Apache Phoenix sind Near-Real-Time Ad-hoc-Analysen sowie Verbesserungen bei Multi-Tenancy möglich, wie es von Hortonworks heißt. In HDP 2.5 ist zudem ein ein Technical Preview von Apache 2.0 Spark enthalten, die die In-Memory-Technologie deutlich schneller machen soll. Spark lässt sich für maschinelles Lernen, ETL und Datenauswertungen verwenden.
Daneben stellt Hortonworks auch “Connected Data Platforms” vor, die ein Management von Data-in-Motion sowie Data-at-Rest in der Cloud und im Rechenzentrum ermöglicht. Die Hortonworks Connected Data Suite verbindet HDP mit Hortonworks DataFlow, der Verwaltung für Data-in-Motion und schlägt damit vereinfacht gesagt, eine Brücke zwischen Data-at-Rest und Daten, die noch im Verarbeitunsprozess sind. Für die neuen Plattformen setzt Hortonworks auch auf eine Distributionsstrategie, die die neuen Features, die in der Apache-Hadoop-Community entstehen, schneller an die Anwender bringen soll.
“Wir glauben, dass unsere volle Ausrichtung auf Open Source, Enterprise-Ready-Funktionen und Benutzerfreundlichkeit zusammen mit der Nutzung der Innovationen aus der Open Community der richtige Weg sind, Connected Data Platforms an Unternehmenskunden zu liefern”, kommentiert Tim Hall, Vice President für Produktmanagement bei Hortonworks. “Der Big-Data-Markt zeigt keine Anzeichen der Verlangsamung und Hortonworks ist dabei gut positioniert, um in diesem Segment entscheidend mitzuwirken.”
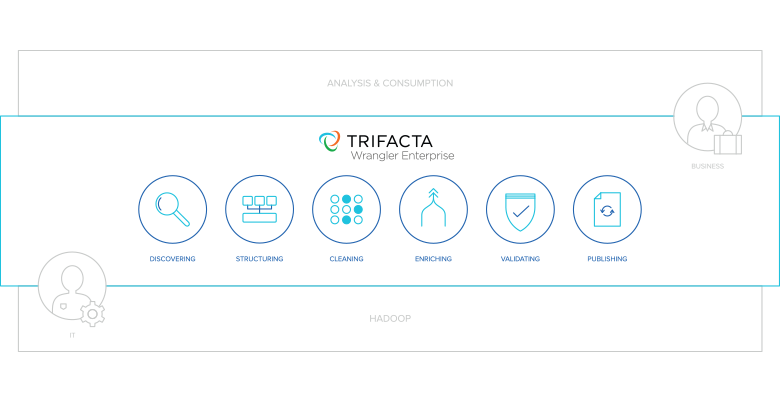
Ebenfalls auf dem Hadoop Summit kündigt der Data-Wrangling-Spezialist Trifacta an, die eigene Lösung für das Vorbereiten von Daten, jetzt tief mit der Hortonworks Data Platform zu integrieren. Daneben präsentiert das 2012 gegründete Start-up die erste Zertifizierung für Apache Atlas. Trifacta, das auf ein Projekt der Universität Berkeley zurückgeht, bietet ein visuelles Tool, über das sich Daten aus ganz unterschiedlichen Quellen und Formaten für die Analyse in Hadoop, Spark oder MapReduce vorbereiten lassen.
Über die Atlas-Integration können Hortonworks-Kunden über Trifacta zudem Metadaten innerhalb der Hortonworks Data Platform verwenden, indem sie diese mit benutzergenerierten Metadaten erweitern. Damit bekommen Datenarchitekten eine schnellen Überblick über sämtliche Metadaten.
Trifacta hat sich auf Hadoop spezialisiert und gilt in diesem Umfeld als derzeit wichtigstes Data-Wrangling-Tool für die quelloffene Big Data Plattform. “Mit Trifacta kann man visuelle Workflows erstellen damit eine Daten-Vorbereitung realisieren, ohne dass man dafür Code schreiben muss”, erklärt Adam Wilson, CEO von Trifacta. Auch Inhalte, die in Hadoop gespeichert sind, lassen sich damit visualisieren. “Man kann damit auch Transformations-Regeln aufstellen und über diese dann über Spark oder MapReduce einen Hadoop-Prozess anstoßen und sich die Daten im gewünschten Format ausgeben lassen”, so Wilson weiter.
Für Trifacta, das mit Accel Partners von dem gleichen Investor finanziert wird wie der Hortonworks-Konkurrent Cloudera, ist die Integration mit Hortonworks zudem ein weiterer wichtiger strategischer Schritt.
Das finnische Facility-Service-Unternehmen ISS Palvelut hat eine umfassende Transformation seiner Betriebsabläufe und IT-Systeme eingeleitet.
PDFs werden zunehmend zum trojanischen Pferd für Hacker und sind das ideale Vehikel für Cyber-Kriminelle,…
Laut Teamviewer-Report „The AI Opportunity in Manufacturing“ erwarten Führungskräfte den größten Produktivitätsboom seit einem Jahrhundert.
Microsoft erobert zunehmend den Markt für Cybersicherheit und setzt damit kleinere Wettbewerber unter Druck, sagt…
Nur 14 Prozent der Führungskräfte in der IT sind weiblich. Warum das so ist und…
Obwohl ein Großteil der Unternehmen regelmäßig Backups durchführt, bleiben Tests zur tatsächlichen Funktionsfähigkeit häufig aus.