Text-to-Speech, also die Umwandlung von Text in gesprochene Sprache, ist einer der Evergreens der IT-Branche. Inzwischen hat die Technik große Fortschritte gemacht, die roboterartigen Stimmen von früher, gehören der Vergangenheit an. Auch wenn es noch deutlich zu früh ist, von “täuschend echt” zu sprechen, heute hören sich die computergenerierten Stimmen schon ganz passabel an.
Vor allem barrierefreie Websites, die inzwischen bei Behörden zum Pflichtprogramm gehören und auch von großen Unternehmen angeboten werden, setzen auf fortgeschrittene Lösungen wie beispielsweise Linguatecs Voice Reader Studio. Daneben lassen sich damit Lehrmaterialien und Präsentationen mit Sprache unterlegen oder Durchsagen generieren. Die Software kostet 499 Euro und ist für den kommerziellen Einsatz konzipiert. silicon.de hat die aktuelle Version 15 einem Test unterzogen.
Nach dem Start des Programms öffnet man eine Textdatei oder kopiert einen Text in das Hauptfenster. Praktischer Nebeneffekt: Die Software öffnet auch PDF-Dateien und verwandelt diese in Text (RTF). Anschließend kann man die Sprache wählen – je nach Version beispielsweise Deutsch oder Englisch – und einen Sprecher aussuchen. Danach lässt man sich den Text probehalber gleich einmal vorlesen.
In der getesteten Version standen vier Sprecher zur Auswahl: “Anna”, “Markus”, “Petra” und “Yannick”. Diese unterscheiden sich beispielsweise in der Tonhöhe. Im Praxistest wirkten “Markus” und “Petra” subjektiv am natürlichsten, was daran liegen mag, dass diese Stimmen etwas tiefer und weicher klingen, so dass Artefakte weniger deutlich zu hören sind. Bei den etwas höheren und härteren Stimmvarianten “Anna” und “Yannick” klingt es irgendwie künstlicher, der digitale Charakter ist deutlicher spürbar. In der Version “britisches Englisch” ist das ganz ähnlich. Hier stehen “Daniel”, “Kate”, “Oliver” und “Serena” als Sprecher zur Verfügung. Im Praxistest gefielen uns “Daniel” und “Serena” am besten.
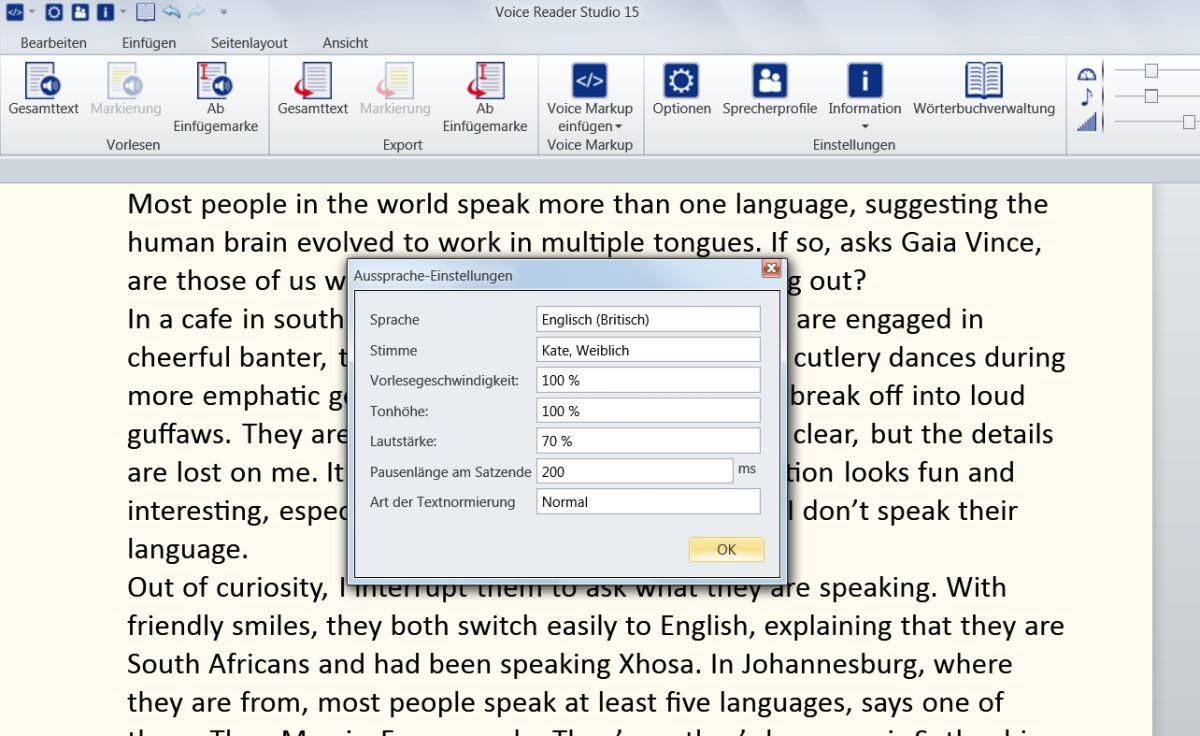
Die Umwandlung in gesprochene Sprache ist mit Voice Reader schon so gut, dass man auch bei längeren Texten problemlos zuhören kann. Verblüffend, wie gut die Software Satzzeichen erkennt und dementsprechend die Betonung verändert. So werden Kommata, Punkt und Fragezeichnen erkannt und die Betonung dementsprechend angepasst. Sätze mit Fragezeichen klingen dann auch wie eine Frage, weil die Stimme des Sprechers am Ende des Satzes hochgeht. Bei Kommata macht der Sprecher eine kleine Pause. Nur Sätze mit Ausrufezeichen werden genauso betont wie solche mit Punkt. Bei Absätzen erfolgt keine besondere Pause. Allerdings lassen sich die Pausen zwischen den Sätzen anpassen. Ebenso kann der Nutzer Parameter wie Tonhöhe, Vorlesetempo und Lautstärke verändern.
Die zentrale Funktion des Programms ist die Umwandlung der Texte in Audiodateien, die man dann beispielsweise auf der Webseite einbaut. Denkbar ist auch, die Audiodateien auf Smartphone zu kopieren und sich dann auf der Reise im Zug vorlesen zu lassen. Die Sprachausgabe erfolgt als MP3 in verschiedenen Kompressions- und Qualitätsstufen von 16 bis zu 320 KBit pro Sekunde. Daneben ist auch unkomprimierte Ausgabe als WAV-File möglich. Hier merkt man aber keine Qualitätsverbesserung mehr. Dafür bietet die digital generierte Stimme einfach nicht genügend Detailinformationen.
Das Umwandeln von Text in eine MP3-Audiodatei läuft recht flott, kann aber bei längeren Texten schon mal etwas dauern. Im Test benötigte ein zehnseitiger Text mit 263 Sätzen insgesamt eine Minute und 20 Sekunden. Ein kürzerer, einseitiger Text mit 26 Sätzen war schon nach 10 Sekunden fertig umgewandelt. Dabei spielt es keine Rolle, welche Kompressionsqualität bei MP3 verwendet wird, nur WAV-Dateien dauern deutlich länger.
Die professionelle Ausrichtung von Voice Reader Studio erkennt man an den zahlreichen Optionen und Einstellmöglichkeiten. So gibt es etwa einen Buchstabiermodus und die Aussprache schwieriger oder ungewöhnlicher Wörter lässt sich korrigieren. Dazu startet man die Option “phonetische Umschreibung”. Hier definiert der Nutzer auf einer virtuellen Tastatur Buchstabe für Buchstabe die gewünschte Aussprache des Begriffs. Zur Kontrolle kann er sich das Wort vorlesen lassen.
Die Funktion ist allerdings nichts für Anfänger, man benötigt etwas Wissen und Erfahrung im Umgang mit Phonetik. Das umfangreiche Handbuch sowie diverse Tutorien auf der Linguatec-Website helfen dabei.
Sehr sinnvoll sind die sogenannten Voice Markups. Damit lässt sich die Audioausgabe nach vielen Kriterien anpassen und auf diese Weise die Monotonie der Computerstimmen aufbrechen. Die Markups kann der Anwender gezielt nur für bestimmte Textpassagen oder sogar nur für einzelne Wörter anwenden. Er verändert beispielsweise die Pausen am Satzende oder passt Geschwindigkeit, Tonhöhe und Lautstärke der gewählten Stimme an.
Hierbei sind der Kreativität keine Grenzen gesetzt. Der Nutzer kann beispielsweise nach Absätzen, die ein Thema abschließen, eine etwas längere Pause setzen oder bei besonders wichtigen Passagen die Lautstärke anheben.
Diese Anpassungen sind vor allem bei längeren Texten sinnvoll, die andernfalls beim Vorlesen schnell langweilig werden. Besonders effektiv ist es, zwischendurch den Sprecher zu wechseln. Sogar Geräusche, Musik oder Sounds lassen sich einfügen. Diese müssen allerdings als WAV-Datei mit Eigenschaften 16 Bit, 22050 Hz, mono vorliegen, sonst funktioniert es nicht.
Das Programm bietet auch sogenannte Multi-Language-Stimmen (ML). Damit lässt sich eine Stimme für mehrere Sprachen einsetzen. Notwendig wird das, wenn in einem Text mehrere Sprachen verwendet werden. Also, wenn beispielsweise in einem deutschen Text ein englisches Zitat eingefügt ist. Allerdings funktioniert das nur bei den Sprechern mit dem Zusatz ML (multi language). Im Deutschen ist das die Stimme “Anna”. Alternativ kann sich der Nutzer so behelfen, dass er beispielsweise für die englische Textpassage eine englischsprachige Stimme definiert.
Die Anweisungen für Sprecherwechsel, Tonhöhe und Lautstärke und so weiter lassen sich praktischerweise auch direkt als XML-Tag in die Textvorlage einfügen. Das hat nebenbei den Vorteil, dass sich die Texte inklusive aller Tags als Textdatei abspeichern lassen und sich so in einem gewöhnlichen Editor weiter bearbeiten lassen.
Voice Reader Studio 15 ist eine leistungsfähige Text-to-Speech-Software. Für optimale Ergebnisse benötigt man viel Zeit, aber es lohnt sich. Denn auf diese Weise kann man interessante und abwechslungsreich gestaltete Hörtexte produzieren.
Mit SAP S/4HANA und Cloud-Technologien legt der Intralogistik-Spezialist Basis für eine zukunftsweisende IT-Architektur.
Automatisiertes Management von iPads sorgt für reibungslosen Betrieb sowie Sicherheit und verlässlichen Datenschutz.
Der aufstrebende Trojaner wird in professionellen Kampagnen eingesetzt, die Plattformen wie TryCloudflare und Dropbox zur…
Investitionsbemühungen der Unternehmen werden nur erfolgreich sein, wenn sie die Datenkomplexität, -sicherheit und -nachhaltigkeit bewältigen…
Generative KI kann falsch liegen oder vorurteilsbehaftete Ergebnisse liefern. Maßnahmen, mit denen Unternehmen das Risiko…
82 Prozent der Unternehmen sind der Meinung, die aktuelle Konjunkturkrise sei auch eine Krise zögerlicher…
{kind=link}
{kind=link}
{kind=link}
{kind=link}