Das Potenzial, das in ihren Datentöpfen schlummert, ist enorm. Um es zu erschließen und tatsächlich Mehrwert zu generieren, braucht es eine klare Strategie. Und eine bessere Zusammenarbeit von Fachbereichen und IT. Damit gewinnt die Schnittstelle zwischen beiden Bereichen an Bedeutung.
Die Daten sind längst da. Entstanden auf der Basis getrennter Systeme, abgelegt in diversen Töpfen, nach unterschiedlichen Standards und oft auch in unterschiedlichen Formaten. Viele dieser Daten werden nach Abschluss der Prozesse, in deren Rahmen sie entstanden sind, nicht mehr genutzt.
Die Strukturen sind über viele Jahre gewachsen, die brachliegenden Datenmengen entsprechend umfangreich.
Der Begriff „Big Data“ drückt es treffend aus: große Datenmengen oder Massendaten. Von „intelligent“ oder „nutzbringend“ ist keine Rede. Inzwischen aber ist klar: Gewinner des digitalen Wandels wird sein, wer in der Lage ist, mit Daten Wertschöpfung zu betreiben. Sie sind der Rohstoff, aus dem zum Teil völlig neuartige Anwendungen und Geschäftsmodelle entstehen.
Zu den größten Hürden der digitalen Transformation zählen der mobile Zugriff auf Unternehmensdaten und Anwendungen, die Nutzung unsicherer Netzwerke und nicht verwalteter Geräte. Das geht aus dem Report „State of Digital Transformation EMEA 2019“ von Zscaler hervor. Jetzt den vollständigen Report herunterladen!
Erstes Ziel für jedes Unternehmen muss heute also sein, den konstruktiven und kreativen Umgang mit Daten zu erlernen. Voraussetzung dafür ist ein systematisches, zielgerichtetes Vorgehen – eine Strategie.
Überblick verschaffen: Daten im eigenen Unternehmen sichten und kategorisieren
Das Problem ist, dass in der Regel niemand im Unternehmen einen Überblick hat, welche Daten überhaupt bereits intern verfügbar sind. Geschweige denn, wo und in welcher Qualität diese Daten vorliegen und wie aktuell sie sind. Meist ist auch nicht geklärt, wem die jeweiligen Daten gehören und wer darauf zugreift.
Die in der Vergangenheit gewachsenen Silo-Strukturen tun ihr Übriges: Teams und Abteilungen arbeiten getrennt voneinander, unternehmensweite Standards, in denen sowohl Form und Qualität der zu speichernden Daten als auch deren Speicherplatz definiert wären, fehlen häufig. Selbst in Großunternehmen, in denen solche Standards mehr oder minder verbindlich existieren, gibt es üblicherweise keine zielführende, nutzenstiftende Gesamtübersicht.
Ziel dieses Ratgebers ist es, SAP-Nutzern, die sich mit SAP S/4HANA auseinandersetzen, Denkanstöße zu liefern, wie sie Projektrisiken bei der Planung Ihres SAP S/4HANA-Projektes vermeiden können.
Es gilt also zuallererst, das eigene Angebot an Daten zu sichten und zu katalogisieren. Grundsätzlich sind Daten geeignet, neue Wertschöpfungsmodelle zu schaffen. Das heißt, sie sind werthaltig. Deshalb sollte man sie wie eine Handelsware betrachten, also wie Produkte, die man verkaufen kann. Durch die Katalogisierung verschafft man sich nach und nach einen Überblick über diese Werte „im eigenen Haus“.
Wie bei Handelswaren ist es wichtig, den „Katalog“ immer auf aktuellem Stand zu halten. Diese geforderte Aktualität erreicht man am besten durch Automatisierung. Der Datenkatalog sollte also am besten über einen klar definierten Prozess oder, noch besser, per Automatismus aktuell gehalten werden.
Von den Daten zum Anwendungsfall oder umgekehrt
Der Rohstoff Daten ist durchaus vergleichbar mit dem Rohstoff Erdöl. Beide wollen exploriert, verfügbar gemacht und aufbereitet werden, um Anwendungen zu unterstützen oder überhaupt erst möglich zu machen. Dazu allerdings muss man wissen, welchem Anwendungszweck das aus dem Rohstoff entstehende Zwischen- oder Endprodukt dienen soll.
Das bedeutet: Fachabteilungen und IT müssen sich zusammentun und eine gemeinsame Sprache finden, um gemeinsam aus dem Rohdatenmaterial wertschöpfende Anwendungen und Geschäftsmodelle entstehen zu lassen.
Dafür empfehlen sich zwei unterschiedliche Ansätze:
Entweder von den Daten zum Anwendungsfall (Bottom Up) oder
über den Anwendungsfall zu den Daten (Top Down).
Für viele Unternehmen ist der Bottom Up Ansatz der einfachere. Dabei gilt es, die folgenden Fragen zu beantworten:
Welche Datentöpfe gibt es im Unternehmen?
Welche technischen Daten werden dort gespeichert?
Wie ist die technische Qualität der Daten pro Datensatz?
Zu welchen fachlichen Daten lassen sich die technischen Daten verdichten?
Beim Top Down Ansatz kommen die Fragen von der fachlichen Seite:
Welche Anforderer gibt es im Unternehmen?
Welche Use Cases haben die Anforderer im Blick?
Welche fachlichen Daten werden pro Use Case benötigt?
Welche dazu passenden technischen Daten haben wir in unserem Unternehmen?
Egal welchen Ansatz man wählt – die Wertschöpfung findet dort statt, wo beide Welten, die IT und die Fachabteilung, zueinander finden. Und das ist durchaus auch eine Frage der gemeinsamen Begrifflichkeiten.
So spricht beispielsweise die IT, ausgehend von den verfügbaren Daten, die ein Fahrzeug generiert, von Längen- und Breitengrad, Höhe über Null oder Wertegenauigkeit und Abweichungen. Für die Fachabteilung, die ihren Use Case betrachtet, wird daraus schlicht eine Positionsbestimmung des Fahrzeugs.
Marc Mai, Senior Software Architect, doubleSlash Net-Business GmbH, hat Wirtschaftsinformatik studiert und verfügt über branchenübergreifende Erfahrungen in IT-Projekten, unter anderem im Bereich Automotive, etwa mit der BMW AG. Er ist Experte für Java-EE, IoT und Big Data. (Bild: doubleslash)
Führt man diese Echtzeit-Positionsdaten zum Beispiel mit Wetter- und Verkehrsdaten zusammen, können die Fahrer einer Flotte jederzeit über die aktuellen Verkehrsverhältnisse informiert werden. Auf dieser Basis sind sie in der Lage, kritischen Situationen auszuweichen. Automatisch integrierte Navi-Daten schaffen hier gegebenenfalls zusätzlichen Nutzen.
Wertschöpfung aus Daten: Externe Datenquellen einbinden
Damit ist bereits der nächste Schritt zur sinnvollen Nutzung von Big Data vorgezeichnet: die Sichtung des Marktes für Daten. Denn wenn ein bestimmtes Anwendungs-Szenario zu realisieren ist, stellt sich die Frage: Sind die dafür nötigen Daten bereits im Unternehmen verfügbar? Wenn nein, gibt es irgendwo auf dem Globus potenzielle Zulieferer?
Das zeigt: Wer sich systematisch mit der sinnvollen Nutzung von Daten beschäftigt, wird früher oder später die Limitierungen auf das eigene Kerngeschäft, die eigenen Kreativpotenziale und die im Hause verfügbaren Daten überwinden. So entstehen dann neue Geschäftsmodelle.
Der Schritt ins Big Data Ökosystem: Eigene Daten vermarkten
Sobald Daten dazu dienen, Anwendungen oder ganze Geschäftsmodelle möglich zu machen, werden sie zum werthaltigen Produkt. Das gilt selbstverständlich auch für die Daten, die das eigene Unternehmen generiert.
Die logische Konsequenz: Eventuell können die Daten meines Unternehmens einem anderen Anbieter nützen, der bereit ist, dafür zu bezahlen. Schließlich helfen diese Daten ihm dabei, seine Geschäftsideen umzusetzen und neue Wertschöpfungsmodelle im Markt zu etablieren.
Entscheidend für den Erfolg der Datennutzung ist also die Fähigkeit, die IT-Seite mit den Ideen und Anforderungen aus den Fachabteilungen zu verknüpfen. Damit gewinnt die Schnittstelle zwischen Fachbereichen und IT an Bedeutung. Je stärker sie systematisiert und automatisiert ist, desto besser wird die Datenstrategie am Ende aufgehen und Nutzen bringen.
Im Rahmen der von techconsult im Auftrag von ownCloud und IBM durchgeführten Studie wurde das Filesharing in deutschen Unternehmen ab 500 Mitarbeitern im Kontext organisatorischer, technischer und sicherheitsrelevanter Aspekte untersucht, um gegenwärtige Zustände, Bedürfnisse und Optimierungspotentiale aufzuzeigen. Jetzt herunterladen!
Mancher Big-Data-Spezialist träumt in diesem Zusammenhang von einem Idealzustand: ein Datenmodell, das so effizient ist, dass man alle relevanten Informationen für die Nutzung und das Handling von Daten fest mit den Daten verbinden kann. Das Ergebnis wäre eine Art Daten-Glossar, anhand dessen sich Daten, die zu bestimmten Zwecken benötigt werden, finden lassen.
So ist zum Beispiel denkbar, das Geschäftsprozessmodell BPMN um eine Ebene zu erweitern. Sie könnte darstellen, welche Daten welcher Use Case benötigt und generiert. Der Vorteil: Dieses Wissen kann in anderen fachlichen Szenarien hilfreich und nutzbar sein.
Damit ein solches Daten-Glossar wirklich Nutzen stiftet, muss es logischerweise automatisierbar sein, nicht zuletzt, um immer den aktuellen Stand zu haben. Und natürlich müssen die technischen Datenmodelle so beschrieben sein, dass die Fachabteilungen damit arbeiten können. Solange es ein solches Glossar nicht gibt, brauchen Unternehmen Übersetzer, die den Transfer zwischen technischen und fachlichen Daten beherrschen.
Die Qualität dieses Transfers ist von elementarer Bedeutung dafür, dass Big Data tatsächlich konkret zur Wertschöpfung eines Unternehmens beiträgt und die digitale Transformation wirtschaftlich Sinn macht.
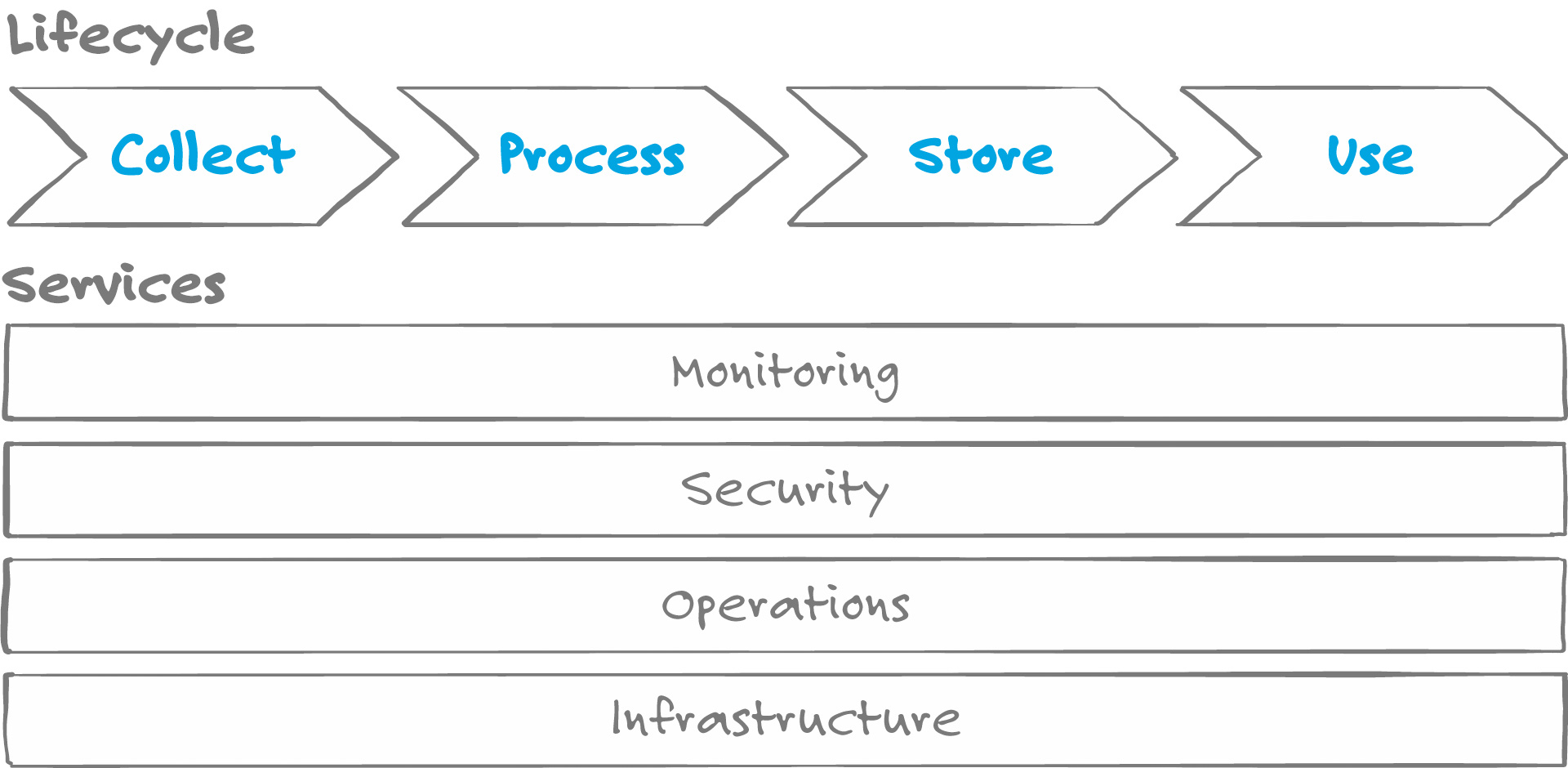
Die Big Data Value Chain
Der digitale Daten-Lebenszyklus lässt sich in vier Phasen aufteilen: Collect, Process, Store, Use. Hier die wichtigsten Punkte, die es beim Aufsetzen eines Big-Data-Systems zu beachten gilt.
Beim Sammeln von Daten (Collect-Phase) können die Daten transformiert, gefiltert, aggregiert oder integriert werden. In dieser Phase sind Fragen zu beantworten wie:
Wie strukturiert oder unstrukturiert sind die verfügbaren Daten? Wie hoch wird der Aufwand sein, um sie zu strukturieren?
Welches Format zum Austausch der Daten soll genutzt werden? Geht man stark spezialisiert vor, riskiert man zu viele künftige Anpassungsprobleme. Geht man generisch vor, wird eventuell ein Overhead an Informationen generiert, die nicht benötigt werden – oder der Verlust an Granularität erschwert später die Nutzbarkeit der Daten.
Wem gehören die Daten, und unter welchen Voraussetzungen dürfen sie eingesetzt werden?
In der Process-Phase ist eine wesentliche Herausforderung, wie Skalierung und Performance zu handeln sind und wie die benötigte Rechenpower sicherzustellen ist. Zu beachten ist auch, dass die Verarbeitung von Daten in der Regel mit kurzen Zeithorizonten verbunden ist. Das kann bei langlebigen Prozessen problematisch werden. Während der Fahrt eines autonomen Fahrzeugs etwa werden ständig neue Informationen generiert. Diese Daten, wie auch der Datenfluss, müssen in ihrer Gesamtheit auch später noch verfügbar sein – werden sie aber im Cache abgelegt, wird das schnell viel zu teuer, da mehr kostenintensive Cache-Kapazität benötigt wird.
Die Store-Phase wirft die Frage auf: Wie fein granuliert sollen die Daten gespeichert werden? Der Spagat zwischen Kosten und Nutzen ist nicht einfach. Stellt man etwa nach Jahren fest, dass man viele Daten hat, die aber für viele Anwendungs-Szenarien zu grob granuliert sind, ist das ebenso unwirtschaftlich wie umgekehrt: Man hat, weil zu fein granuliert, viel mehr Daten gespeichert als man je benötigt. Hier potenziert sich die kleinste Fehleinschätzung über die Jahre und die Menge an Daten um große Faktoren.
Auch der Speicherort will wohl überlegt ausgewählt sein. Oft ist es kostengünstiger, externe Speicherkapazitäten wie Cloudservices zu nutzen. Dabei ist aber genau zu klären, welche Daten wo abgelegt werden. Verbindliche Vertraulichkeitskriterien sind hier von entscheidender Bedeutung. Ideal ist es, wenn das System die jeweiligen Daten anhand dieser Kriterien automatisch am richtigen Speicherort ablegt.
In der Use-Phase kommt es schließlich darauf an, die Anforderungen der Zielgruppe richtig abzubilden. Auch hierbei spielen Granularität und Qualität der Daten eine wesentliche Rolle, aber auch deren Aufbereitung: Wie weit muss ich die technischen Daten abstrahieren, damit meine Zielgruppe sie versteht und damit umgehen kann?