Von der zunehmend digitalisierten Wirtschaft und Gesellschaft werden immer mehr Daten generiert – eine Einzelperson beispielsweise erzeugt pro Tag rund 1,5 GByte Daten, eine vernetzte Fabrik 1 TByte und mehr. Um Nutzen zu entfalten, müssen sie gespeichert und analysiert werden, und zwar möglichst schnell. Nur so können die aus den Daten generierten Einsichten zum Motor neuer Geschäftsprozesse werden. Deshalb steigen die Anforderungen an Storage-Systeme: Sie müssen heute nahezu ununterbrochen verfügbar sein. Ausfälle werden schnell extrem teuer. So kann eine Stunde Ausfallzeit nach einer Untersuchung von The Aberdeen Group aus dem Jahr 2016 durchaus mittlere sechsstellige Beträge pro Stunde kosten.
Gleichzeitig stehen IT-Abteilungen unter Kostendruck: Hochverfügbarkeit der Systeme soll bei steigenden Kapazitäten zu gleichen oder geringeren Kosten realisiert werden als bisher. Die klassischen Technologien auf dem Weg zur kontinuierlichen Verfügbarkeit waren zwei- oder mehrfach redundante Infrastrukturen, gepaart mit aufwändigen Softwaremechanismen. Sie kosteten sehr viel Geld und erforderten spezialisiertes Personal und teure Wartungsverträge. Doch das IT-Personal, eine rare Ressource, soll seine Kapazitäten lieber kerngeschäftsnahen Aufgaben widmen statt sie an Routine und Fehlerbehebungen zu verausgaben.
Rein technologisch steigt die Komplexität: Storage-Systeme sind mehr denn je eingebunden in mehrschichtige, zum Teil hybride Infrastrukturen, deren Ebenen sich wechselseitig beeinflussen und auch stören können. Fehler, Ausfälle oder unbefriedigende Leistungen der Storage-Systeme können ihre Ursache auf irgendeiner Ebene des Infrastruktur-Stacks haben, nicht notwendigerweise liegt sie in der Storage selbst. Server-Settings, eine bestimmte Netzwerkkonfiguriation, eine Softwareversionen von Betriebssystem oder Hypervisor oder das Zusammenwirken irgendwelcher anderen Komponenten können die Funktionen des Storage-Systems stören. Oft genug treten Inkompatibilitäten zwischen einzelnen Softwareelementen nur bei einem bestimmten Versions-Mix auf. Solche Fehler sind normalerweise sehr schwer zu finden. Diese Situation führt in Infrastrukturen mit konventionellen Storage-Systemen häufig dazu, dass es lange dauert und sehr teuer ist, Störungen mit vielfältigen Ursachen, die sich letztlich am Storage-System zeigen, zu beheben.
Das dafür nötige Wissen übergreifend zu generieren war bisher nahezu unmöglich – meist besaßen es nur wenige Infrastrukturspezialisten beim Hersteller oder im Anwenderunternehmen aufgrund langjähriger Erfahrung. Wechselten sie den Arbeitgeber, nahmen sie ihre Kenntnisse mit.
Im Bewusstsein dieser Situation entschied sich HPE Nimble Storage von Anfang an für ein grundlegend anderes Daten- und Analyse-getriebenes Servicekonzept, das weit über die üblichen Sicherungsmechanismen gegen Ausfälle hinausgeht. Trotzdem sind natürlich alle Systemvarianten ausfallsicher konstruiert („no single point of failure“). So haben die Geräte zwei Controller, die sich wechselseitig ersetzen können, eine fehlertolerante Softwarearchitektur und robuste Datenintegritätsmechanismen bis hin zu Dreifach- und Paritäts-RAID (Redundant Array of Independent Disks). Die Datenintegrität wird von Ende zu Ende validiert.
Verfügbar sind zwei Varianten von HPE Nimble Storage: Die Serie HPE Nimble Storage All-Flash-Array (AF) eignet sich für Applikationen mit besonders hohen Leistungsansprüchen im echtzeitnahen Bereich. Die Rohkapazitäten dieser Geräteserie liegen zwischen fünf und 126 TiB (Tebibyte) und nutzbaren Kapazitäten zwischen 4 und 124 TiB, inklusive Kompression und Deduplizierung entspricht das 189 bis 620 TiB Rohdaten. In der höchsten Ausbaustufe mit vier Arrays fasst ein All-Flash-System bis zu 2,4 PiB (Pebibyte).
Die HPE Nimble Storage Adaptive-Flash-Arrays der CS-Serie kommen mit kundenspezifisch wählbaren Anteilen von Flash-Cache und Festplatten. Hier liegt die Maximalkapazität bei knapp 1,5 TByte, die nutzbare Kapazität bei maximal knapp 1,2 TByte und die effektive Kapazität bei knapp 2,4 TByte. Hier sind bis zu sechs Erweiterungsgehäuse möglich, von denen jedes bis zu 21 Speichereinheiten fasst – jeweils wahlfrei Flash-Cache oder Festplatten. Diese Geräte verwenden einen Schreibmechanismus, der auf schnell wechselnde Workloads optimiert ist und eignen sich deshalb gut als „Arbeitspferde“ in Unternehmensumgebungen für die alltäglich genutzten betriebswichtigen Applikationen. Service Level lassen sich für jedes Volume separat auf Knopfdruck festlegen, wobei Anwender zwischen drei Serviceniveaus mit unterschiedlichem Flash-Anteil wählen können.
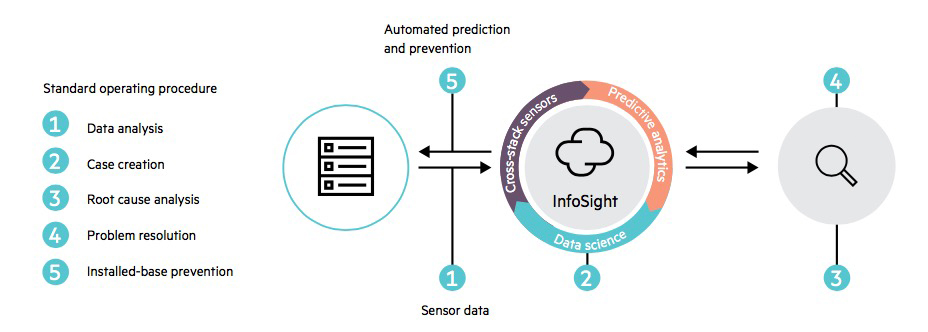
Doch worin liegt nun der konzeptionelle Unterschied zu anderen, vergleichbaren Produkten? Nimble implementierte von Anfang an Tausende Softwaresensoren an wichtigen Stellen seines Betriebssystem-Codes. Die arbeitenden Nimble-Systeme sind mit dem Netz verbunden. So liefern die integrierten Sensoren ihre Daten an eine zentrale InfoSight-Instanz in der InfoSight-Cloud. Das Cloud-Tool HPE InfoSight Predictive Analytics sammelt die Daten aller Nimble-Systeme, analysiert sie und generiert daraus Wissen über optimale Settings, Fehlerquellen und mögliche Lösungen. Es abstrahiert die an den Systemen einzelner Kunden oder IT-Infrastrukturen gewonnenen Erfahrungen und Einsichten und produziert Implementierungsempfehlungen, Lösungsanweisungen für Störungen oder automatisierte Mechanismen, die Systemausfälle oder -störungen meist schon vorausschauend verhindern. Dieses Wissen steht allen Nimble-Anwendern im Rahmen des regulären Service ohne Aufpreis zur Verfügung.
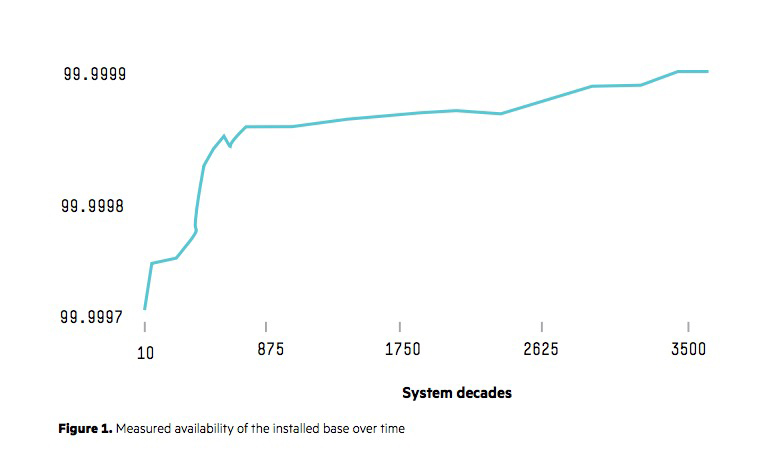
Mit dieser Methode erreichte HPE Nimble bereits 2014, als HPE den bis dahin unabhängigen Storage-Anbieter aufkaufte, eine Verfügbarkeit von „fünf Neunen“ (99,999%). Weil Infosight Precitive Analytics jeden Tag dazulernt, ist der Verfügbarkeitswert inzwischen auf 99,999928 % gestiegen – das sind nur noch 25 Sekunden Ausfallzeit jährlich. Die prozentuale Verfügbarkeit wird dabei als Durchschnitt der real arbeitenden gesamten Gerätebasis berechnet, nicht an irgendwelchen fiktiven Konstellationen. Dazu gehören Systeme mit unterschiedlichen Konfigurationen, Systemumgebungen und Betriebssystemversionen.
Die extrem hohe Verfügbarkeit spiegelt zudem nicht nur das Verhalten aktueller Systeme wieder, sondern das aller – von den ersten implementierten und noch im Markt befindlichen HPE-Nimble-Systemen, die etwa vor sechs Jahren den Betrieb aufnahmen, bis zu der aktuellen, die gerade erst den Betrieb aufnehmen.
So werden auch neueste Technologien von Anfang an einbezogen, denn Nimble passt sich stetig an die Weiterentwicklungen der Storage-Technologie an: Kürzlich präsentierte HPE die nunmehr dritte HPE-Nimble-Systemgeneration. Sie ist auf den Einsatz neuer, persistenter Storage-Medien wie NVMe und Storage Class Memory vorbereitet, die die Leistungslücke zwischen DRAM im Arbeitsspeicher und NAND-SSDs als Massenspeichermedium schließen sollen. Die beiden neuen Speichertypen arbeiten bis zum Tausendfachen schneller als klassische NAND-Flash-SSDs und eröffnen damit völlig neue Leistungshorizonte. Sie werden sich in den nächsten Jahren sehr wahrscheinlich als eigenständige Speicherschicht etablieren. Auch HPE-Nimble-Systeme mit diesen neuen Speicherklassen werden von Anfang an in Infosight Predictive Analytics eingebunden.
Weil Infosight jeden Tag neue Daten erhält, auswertet und so seine Wissensbasis erweitert, spricht nichts dagegen, dass die Verfügbarkeit von HPE Nimble Storage weiter zunehmen wird – bis hin zum real unterbrechungsfrei verfügbaren System.
Dabei misst HPE InfoSight misst die Verfügbarkeit jedes angeschlossenen Systems auf die Mikrosekunde genau. Ausfallzeiten erfasst InfoSight automatisch, kategorisiert und archiviert sie. Nicht als Ausfallzeiten zählen lediglich geplante Wartungszeiten, generelle Stromausfälle und andere Events, bei denen der Ausfall eines Gerätes nichts mit der Funktion dieses Geräts oder seiner IT-Systemumgebung zu tun hat. Sie werden nicht erfasst.
Störfälle fasst InfoSight über die gesamte Gerätebasis nach Betriebssystemvariante, Softwarerelease, Modell oder nach anderen Kriterien, beispielsweise dem Hypervisortyp, zusammenfassen und analysiert sie. Jeder Störfall wird auf die zugrundeliegende Ursache hin untersucht. Anschließend wird eine Lösung erarbeitet und der Störfall mit einer Signatur versehen. InfoSight sucht in der angeschlossenen Systembasis nach genauso konfigurierten Systemen und stellt diesen den Workaround proaktiv zur Verfügung.
Infosight analysiert aber nicht nur die HPE-Nimble-Storage-Systeme bei den über 12.000 Kunden, sondern auch deren gesamte IT-Umgebung, soweit das mit Hilfe der verfügbaren Sensoren und der von ihnen erzeugten Daten möglich ist. Wie schon oben erwähnt, liegt nämlich der Grund für Storage-Ausfälle oder Zugriffsverzögerungen oft gar nicht im Speichersystem, sondern in anderen, mit ihm verbundenen Infrastrukturkomponenten – nach praktischen Erfahrungen bei Nimble-Kunden in 54% der Fälle. Nur wer die entsprechenden Kausalitäten ergründen kann wie HPE InfoSight hat eine Chance, dauerhaft zu höheren Verfügbarkeiten zu kommen.
Wenn HPE InfoSight bei der Analyse der Millionen Datenpunkte, welche die unzähligen Sensoren in den HPE-Nimble-Systemen weltweit ständig erzeugen, ein potentielles Problem entdeckt, wird ein Fall eröffnet. Dasselbe geschieht, wenn ein Kunde ein Problem meldet. Dabei eröffnet InfoSight rund 90 Prozent der Fälle selbst und löst 86 % aller Fälle selbsttätig, bevor Nimble-Anwender überhaupt hätten registrieren können, dass ein Problem entstehen könnte.
Um Ursachen von und Lösungen für besonders komplexe Störungen in IT-Infrastrukturen zu finden, wurde zudem ein spezielles Ingenieursteam, das PEAK-Team, gebildet. Seine Mitglieder besitzen Erfahrung in der schichtübergreifenden Analyse von IT-Infrastrukturen. Jeder Fall von Kunden oder dem System generierte Fall wird einem PEAK-Team-Mitglied zugewiesen. Es sucht mit Hilfe von InfoSight und anderen technischen Spezialisten nach der Ursache, egal, wo sie sich befindet.
Zwei Beispiele: In einem Fall konnten ein spezifischer virtueller Netzwerkadapter und die Nimble-Software nicht zusammenarbeiten. Die mögliche Folge: Der Wiederaufbau von Fibre-Channel-Verbindungen wäre möglicherweise durch einen doppelten Portabwurf der Schnittstellenkarte bei den betreffenden Anwendern blockiert worden und das hätte einen katastrophalen Fehler verursachen können. Das PEAK-Team entwickelte mit Hilfe von InfoSight eine Umgehungslösung, versah den Fehler mit einer Signatur-ID und verteilte die Lösung über diese Signatur-ID an alle Kunden, die dieselbe Systemumgebung hatten und deshalb von dem Problem hätten betroffen sein können.
In einem anderen Fall meldeten sich während eines NimbleOS-Updates plötzlich die Volumes des Kunden ab. Es zeigte sich, dass die Ursache dafür ein Fehler in der Hypervisor-Software war. Auch hier konnte Nimble schleunigst eine Umgehungslösung entwickeln und das Problem mit einer Signatur kennzeichnen. Anschließend wurden Kunden, die denselben Hypervisor nutzten, automatisch daran gehindert, auf die betreffende Version von NimbleOS zu aktualisieren, bis der Fehler im Hypervisor behoben war. Das bewahrte viele Nimble-Anwender davor, denselben gravierenden Vorfall zu erleben. Die mit der Zeit stetig steigende Zahl der Signaturen beweist, dass es immer mehr derartige proaktive Lösungen gibt, dass also immer mehr subtile Fehlerquellen aufgespürt und neutralisiert werden, bevor sie in Anwenderumgebungen zu Problemen führen.
Letzteres Beispiel ist keine Ausnahme: Hinsichtlich sämtlicher Systemaktualisierungen verwendet das PEAK-Ingenieurteam eine Schwarze Liste, die Kunden mit bestimmten Systemkonfigurationen daran hindert, ihre Nimble-Systeme auf bestimmte NimbleOS-versionen zu aktualisieren, um Inkompatibilitäten und daraus resultierende Störungen schon im Vorfeld auszuschließen. InfoSight erstellt zudem auf die individuelle Anwender-Infrastruktur zugeschnittene Upgrade-Pfade. Dadurch können Nimble-Kunden davon ausgehen, dass ihre Upgrades sicher sind und sich bereits jemand der bei ihnen eventuell möglichen Kompatibilitätsprobleme angenommen hat.
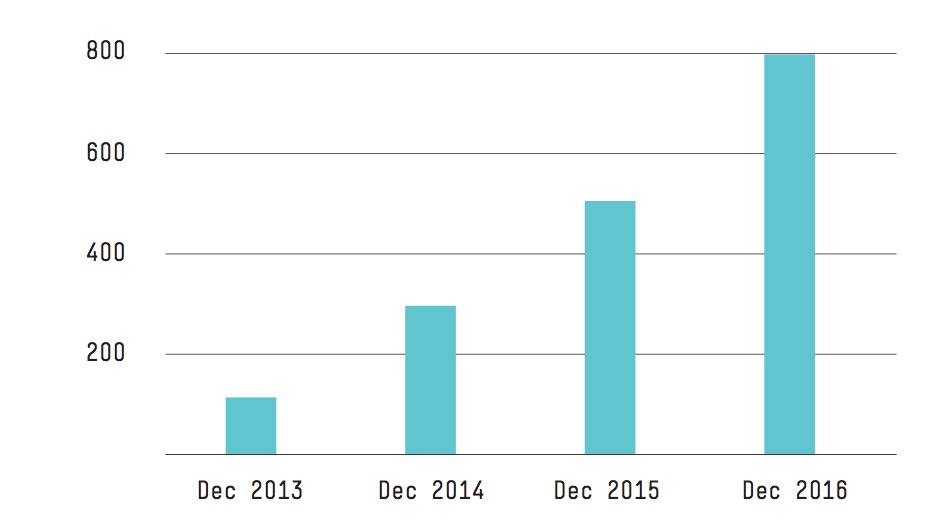
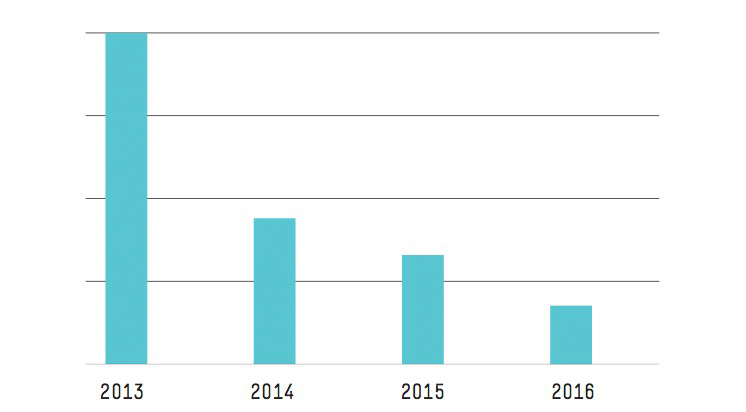
Insgesamt hat die Zahl der Supportfälle, in denen Kunden selbst aktiv werden mussten, wegen dieser Mechanismen seit 2013 im Jahr um durchschnittlich 19,3 Prozent abgenommen, obwohl sich die Zahl der Kunden verneunfacht hat. Dazu kommen die unübertroffene Verfügbarkeit von 99,999928 % und der Möglichkeit, nun auch die nächste Speichergeneration, NVMe oder SCM, ohne gravierende Systemänderungen zu implementieren. Das alles macht HPE InfoSight Nimble Storage zu einer zukunfts- und investitionssicheren Storage-Plattform, die auch höchsten Leistungs- und Verfügbarkeitsanforderungen gewachsen ist.
Das finnische Facility-Service-Unternehmen ISS Palvelut hat eine umfassende Transformation seiner Betriebsabläufe und IT-Systeme eingeleitet.
PDFs werden zunehmend zum trojanischen Pferd für Hacker und sind das ideale Vehikel für Cyber-Kriminelle,…
Laut Teamviewer-Report „The AI Opportunity in Manufacturing“ erwarten Führungskräfte den größten Produktivitätsboom seit einem Jahrhundert.
Microsoft erobert zunehmend den Markt für Cybersicherheit und setzt damit kleinere Wettbewerber unter Druck, sagt…
Nur 14 Prozent der Führungskräfte in der IT sind weiblich. Warum das so ist und…
Obwohl ein Großteil der Unternehmen regelmäßig Backups durchführt, bleiben Tests zur tatsächlichen Funktionsfähigkeit häufig aus.