Die meisten Unternehmen nutzen heute den einen oder anderen Public-Cloud-Services. Dienste wie Salesforce.com oder Google Analytics sind aus dem Unternehmensalltag kaum noch wegzudenken. Neben solchen speziellen Services werden auch immer mehr klassische IT-Lösungen in die Cloud verlagert: Datenreplikation, Backup, E-Mail, ja, sogar ERP-Software oder klassische Datenbanken. Eine Zukunftsvision ist, dass Unternehmen neben ihrer on-Premises-Cloud in Zukunft selbstverständlich mit mehreren Public-Cloud-Providern zusammenarbeiten und auch Lasten zwischen diesen Cloud-Partnern mehr oder weniger beliebig verlagern können (sog. Multicloud).
Gleichzeitig haben die Unternehmen in der Regel weiterhin Rechenzentren, wo vorzugsweise besonders produktions- und betriebswichtige Applikationen und Daten untergebracht und betrieben werden. Darüber, was im eigenen Rechenzentrum und was in der Public Cloud betrieben wird, entscheiden unterschiedliche Gesichtspunkte.
Die Argumente für die Migration einer Anwendung in die Cloud sind häufig kosten- oder flexibilitätsorientiert: Ein Cloud-Service skaliere nach Wunsch, erzeuge nur vorhersehbare Kosten nach Verbrauch, erspare den Unternehmen kostspielige Investitionen in Hardware und könne schnell abbestellt werden. Interne Infrastruktur dagegen sei unflexibel, habe lange Bereitstellungszeiten, erfordere große Investitionen, werde erst mit der Zeit ausgelastet, wenn überhaupt, und verursache hohen Integrations-, Wartungs- und Supportaufwand.

Diese Argumentation spiegelt die Situation zu Zeiten getrennter Infrastruktur-Silos und des damit verbundenen Aufwandes wider. Tatsächlich erfordern Systeme, in denen Speicher, Server und Netzwerke konsequent voneinander getrennte Welten darstellen, eine komplexe Verwaltung. Mit der Virtualisierung von immer mehr Komponenten sind aber diese Grenzen zunehmend dabei zu verschwimmen – allerdings ist konventionelle Infrastruktur auf virtualisierte Umgebungen nur unvollkommen ausgerichtet.
Doch inzwischen sind hyperkonvergente Infrastrukturen als neue Infrastrukturvariante entstanden und bilden ein schnell wachsendes Marktsegment des IT-Marktes. Sie beseitigen die meisten der Flaschenhälse und Probleme herkömmlicher Infrastrukturen, dank derer Public-Cloud-Services von AWS, Google oder Microsoft Azure bislang meist günstiger gegenüber der herkömmlichen „Silo-IT“ erschienen: Sie vereinigen Compute- und Storage-Komponenten in einem Modul, kommen mit eigenem Hypervisor und damit integrierter Management-Software und sind auf einfache Skalierbarkeit durch das Hinzufügen neuer Rechenknoten ausgelegt, was keinen neuerlichen Integrationsaufwand erfordert.
Gleichzeitig setzen HCI-Systeme nicht ausschließlich auf den immer noch teuren Flash-Speicher, sondern kombinieren Flash und rotierende Speichermedien so, dass optimale Leistungen bei minimalen Kosten zustande kommen. Sie verwenden modernste Infrastrukturkomponenten und lassen sich schrittweise durch das Hinzufügen neuer Knoten ausbauen und modernisieren. Ein hyperkonvergentes System betriebsbereit zu machen, dauert maximal einige Stunden, nicht Wochen oder Monate wie bei herkömmlichen Systemumwelten, weil Integrationsfragen vom Hersteller bereits im Vorfeld gelöst wurden.
Hyperkonvergente Systeme für Unternehmen wie HPE Simplivity besitzen in der Regel eine komfortable, nutzerfreundliche Bedienoberfläche im Cloud- oder Web-Stil, die leicht zu erlernen ist. Ihre Management-Software ist von vorn herein auf die Arbeit mit virtuellen Maschinen, nicht mehr physischen Servern wie traditionelle Systemmanagementlösungen, ausgelegt. Das bedeutet, dass viele Probleme rund um das Speichern der Daten virtueller Maschinen vom Hersteller mitbedacht und damit für den Anwender gelöst wurden.
Ein wichtiges Beispiel dafür ist, dass die Verwaltung konventioneller Speichersysteme auf LUNs (Logical Units) zugeschnitten ist, auf die bestimmte Server zugreifen, und nicht auf virtuelle Maschinen. Weil auf einem Server in der Regel mehrere virtuelle Maschinen (VMs) liegen, konkurrieren diese VMs um den Speicherraum desselben Servers, also dieselbe LUN, und können sich beispielsweise bei der Speicherbelegung oder bei Datenzugriffen gegenseitig ausbremsen oder behindern. Das bezeichnet man als I/O-Blending.
Die Konsequenz: Die Leistung sinkt, das Management von VMs gestaltet sich kompliziert, weil es sich mit dem von Servern und LUNs überlagert. HCI-Infrastrukturen dagegen lösen sich von LUNS und Servern als Zuordnungseinheiten. Sie betrachten die VM mit dem ihr zugeordneten Speicher, nicht den Server oder beim Speicher eine LUN als grundlegende Einheit, womit beispielsweise das Problem des I/O-Blending entfällt. Auch ein Backup einzelner Maschinen ist auf diese Weise einfach möglich, genau wie die Entwicklung eines spezifischen Regelsatzes für jede einzelne VM und damit jede Applikation, die auf einer VM läuft.
Dazu kommt eine große, auf den professionellen Unternehmensbedarf zugeschnittene Funktionsvielfalt: HCI-Systeme, die auf den Bedarf professioneller Anwender zugeschnitten sind wie HPE Simplivity, besitzen als Bestandteil der mitgelieferten Software Funktionen wie Datenreduktion, Replikation, Journalling, Verschlüsselung der Daten oder Disaster Recovery, für die Anwender normalerweise viel Geld bezahlen müssen. Oft sind sie auch mit Gateway-Technologien für die Public Cloud ausgerüstet und können damit unkompliziert in eine hybride Infrastruktur integriert werden. Zudem verursachen solche Lösungen wenig Aufwand für Integration, Schulung, Wartung und Support.
Dazu kommt, dass unternehmenswichtige Daten auf einer on-Premises-Cloud auf Basis eines HCI-Systems unter voller Kontrolle des Unternehmens bleiben – gerade im Zeitalter forcierten Datenschutzes ein gewichtiges Argument insbesondere in Europa. Zudem ist ein Unternehmen, das eine On-Premises-Cloud auf HCI-Basis betreibt, in geringerem Umfang den Unwägbarkeiten beim Datentransport übers WAN ausgesetzt. Denn wenn aus irgendwelchen Gründen die Netzverbindung versagt, ist selbst der an sich leistungsfähigste und kostengünstigste Public-Cloud-Service sinnlos.
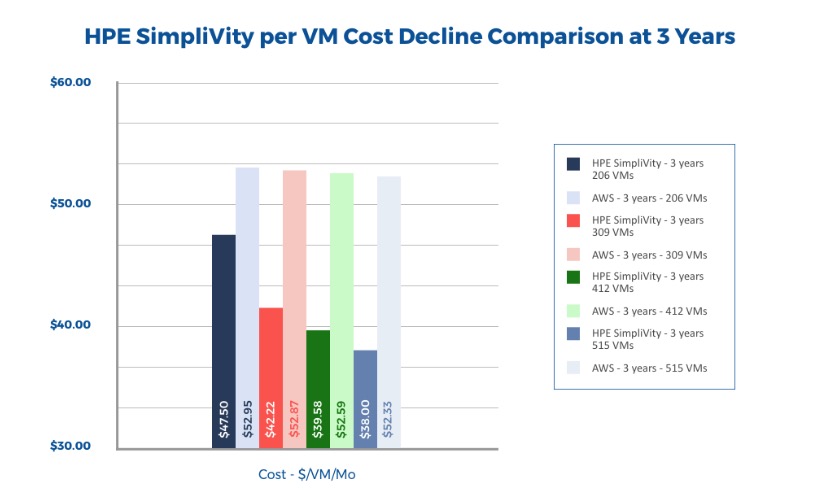
Eine aktuelle Analyse der Evaluator Group untersuchte genauer, wie sich die Kosten von Public Cloud und HCI zueinander verhalten. Sie vergleicht die Gesamtkosten (Anschaffung und Betrieb) einer HPE Simplivity 380 in n+1-Konfiguration mit drei, vier, fünf und sechs Knoten, von denen jeder 103 virtuelle Maschinen fasst, mit gleich leistungsfähiger Infrastruktur bei AWS über eine Nutzungsdauer von drei Jahren, einer in Unternehmen üblichen Abschreibungsperiode für IT-Equipment. Unter n+1 wird verstanden, dass n Arbeitsknoten ein Knoten gegenübersteht, der bei Störungen die Aufgaben des ausfallenden Knotens nahtlos übernehmen kann. Die kleinste berechnet Konfiguration fasste also 206 virtuelle Maschinen (2 Knoten zu je 103 Maschinen plus ein Ersatzknoten).
Die Grundlage der Kalkulation der AWS-Kosten bildeten die Preise der Zone US-East. Berechnet wurden Konfigurationen für 206, 309, 412 und 515 VMs. Pro Instanz wurde eine M3-Compute-Instanz mit einer virtuellen CPU und 3,73 GByte Memory bei 100 Prozent Nutzungsgrad, dafür jeweils 100 GByte General-Purpose-SSD, eine Speicher-Ein-/Ausgabeleistung von 100 IOPS, Snapshots mit einer täglichen Veränderungsrate von 10% der Daten, pro Monat 1 TByte an AWS überspielte und 3 TByte von AWS zurückgespielte Daten je 103 Instanzen angenommen. Zwischen jeweils 103 Instanzen wurde von einem internen Datentransfer von 6 TByte ausgegangen. Außerdem wurden Kosten für AWS-Business-Support für alle Services hinzugerechnet.
Bei HPE Simplivity wurden der Anschaffungspreis für die HPE Simplivity 380 zum Listenpreis abzüglich eines Standard-Discounts eingerechnet, drei Jahre Wartung für die angeschafften Knoten, v-Sphere-Lizenzen für jeden Knoten mit zwei CPUs und Support für vSphere, wobei in beiden Fällen ein Standard-Discount von 10 Prozent vom Listenpreis abgezogen wurde. Dazu kommen Energie, Kühlkosten und Flächenverbrauch in Höhe von 100 Dollar monatlich pro Knoten sowie die Administration. Annahme war, dass für jeden Knoten eine Stunde wöchentlicher Wartungsaufwand anfällt, wobei ein Stundensatz von 75 Dollar für den Administrator veranschlagt wurde.
Es ergaben sich für die AWS-Variante Gesamtkosten von 10.907 Dollar pro Monat, das sind 52,95 pro VM, für die HPE-Simplivity-Infrastruktur 9.784 Dollar pro Monat, das sind 47,50 Dollar pro VM. Mit anderen Worten: HPE Simplivity erwies sich bei den Gesamtkosten als letztlich um zehn Prozent günstiger als die Verwendung von AWS. Die Relation verschlechtert sich noch, wenn die Infrastruktur bei AWS on demand oder mit kürzerer Verragsdauer bestellt wird.
Die Skalierung eines HCI-Systems besteht in erster Linie darin, dass ihm neue Knoten hinzugefügt werden. Jeder neue Knoten erhöht die Zahl der möglichen virtuellen Maschinen bei der gewählten Beispielrechnung um 103 virtuelle Maschinen. Es wurden in drei Schritten neue Maschinen hinzugefügt, so dass 309, 412 und 515 VMs unterstützt werden konnten.
Zum Vergleich wurde auch die AWS-Infrastruktur entsprechend aufgestockt und dann wiederum die Kosten berechnet. Instinktiv würde man annehmen, dass sich bei AWS große finanzielle Skalierungsvorteile ergeben, doch das Gegenteil ist der Fall: die Kosten pro VM fallen mit steigender Systemgröße auf HPE Simplivity bis auf 38 Dollar pro VM und Monat, während sie bei AWS nur geringfügig abnehmen. Dabei wurde die günstigste AWS-Preisvariante mit dreijähriger Vertragsbindung angenommen.
Hier zeigen sich die langfristigen ökonomischen Vorteile des HCI-Modells mit aller Deutlichkeit: Offene Standardhardware, Integration von Server und Storage, geringer Installations- und Erweiterungsaufwand, vorinstallierte Services wie Datensicherung, geringerer Speicherbedarf durch integriete Deduplizierung. Weil das VM-Management im Hypervisor steckt, ist es möglich, mehr VMs in der gleichen Zeit zu verwalten. Zudem lassen sich für jede VM einfach separate Management-Regeln definieren, was Sicherheit und Handhabung des Systems erheblich vereinfacht und insgesamt den Personalbedarf und das notwendige Qualifikationsniveau der Administratoren verringert.
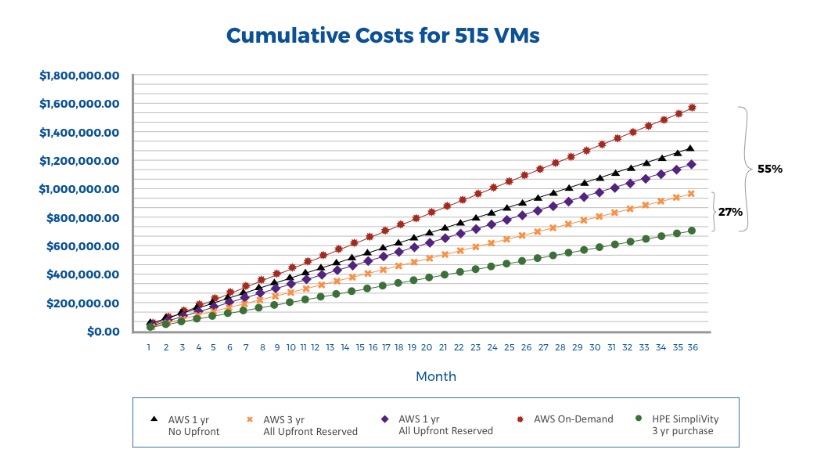
Noch deutlicher wird der Kostenvorteil von HPE Simplivity, wenn man die kumulativen Kosten betrachtet. Je nach dem gewählten Bezugstyp machen die Gesamtkosten einer Infrastruktur für 515 VMs bei AWS über drei Jahre zwischen 970.000 und 1,57 Millionen Dollar aus. Das ist eine erhebliche Spannbreite. Doch auch die günstigste AWS-Variante – Buchung der kompletten Infrastruktur für die 515 Maschinen für drei Jahre von Anfang an – kostet noch immer 27 Prozent mehr als dieselbe Leistung, wenn sie mit HPE Simplivity realisiert wird. Denn hier kostet ein drei Jahre genutztes System für 515 VMs (5+1 Knoten) nur 704.000 Dollar. Die teuerste Variante der AWS-Infrastruktur, die Bestellung von 515 VMs on demand, ist demgegenüber doppelt so teuer.
Dazu kommt, dass auch der Public-Cloud-Gebrauch Tücken birgt: So hat sich herausgestellt, dass gerade die einfache Möglichkeit, neue Ressourcen zu bestellen, dazu führt, dass der Überblick über die gebuchten Ressourcen leicht verlorengeht. Dann befinden sich viele VMs auf der Rechnung eines Anwenders, ohne dass er damit noch etwas anfängt. Auf einer HCI-Infrastruktur mag es zeitweise ebenfalls zu einem „VM-Sprawl“ kommen, doch schlägt dieser weit weniger kräftig zu Buche. Zudem bleiben Anwender von unerwarteten rechtlichen Änderungen oder Änderungen in der Preispolitik des Anbieters, die bei Cloud-Providern gang und gäbe sind, unberührt.
Eine Hybrid Cloud, die sinnvoll einsetzbare Public-Cloud-Services – einige Beispiele finden sich am Anfang des Artikels – und eine On-Premises-Cloud für die Kernanwendungen des Unternehmens auf HCI-Basis kombiniert, könnte sich also kostenseitig und auch aus anderen betrieblichen Gründen als optimale IT-Infrastruktur für Unternehmen erweisen. Dies gilt erst recht, da mit HPE GreenLake Flex Capacity nun auch für HPE Simplivity ein Cloud-ähnliches nutzungsbasiertes Betriebs- und Abrechnungsmodell verfügbar ist, bei dem die Kosten mit dem Bedarf des Unternehmens wachsen und Vorinvestitionen in Infrastruktur unnötig macht. Berechnet wird hier nur, was auch genutzt wird, und ein lokaler Ressourcenpuffer sorgt dafür, dass Skalierungsschritte umgehend erfolgen können, wenn die Leistungsnachfrage es verlangt. Nicht sinnvoll ist es dagegen, wie die obigen Kalkulationen zeigen, unreflektiert die meisten wichtigen Apps und VMs in die Cloud zu verlagern.
Microsoft erobert zunehmend den Markt für Cybersicherheit und setzt damit kleinere Wettbewerber unter Druck, sagt…
Nur 14 Prozent der Führungskräfte in der IT sind weiblich. Warum das so ist und…
Obwohl ein Großteil der Unternehmen regelmäßig Backups durchführt, bleiben Tests zur tatsächlichen Funktionsfähigkeit häufig aus.
Laut ESET-Forschern hat sich die Gruppe RansomHub innerhalb kürzester Zeit zur dominierenden Kraft unter den…
Damit hängt die hiesige Wirtschaft beim Einsatz der Technologie zwar nicht zurück, ist jedoch auch…
Bitdefender-Labs-Analyse der ersten digitalen Erpressung von RedCurl zeigt, dass Angreifer lange unentdeckt bleiben wollen und…