Welcher Data-Scientist-Typ sind Sie? SAS bietet einen Persönlichkeitstest für Datenwissenschaftler an. (Bild: SAS)
Solange die Datenmengen sehr klein sind, tun ein Texteditor oder Excel ja gute Dienste. Sobald man diese Zone allerdings verlässt wird es schnell sehr (sehr!) mühsam.
Bei der Datenaufbereitung gibt es verschiedene Abstraktions-Layer – je weiter unten desto aufwändiger die Manipulation der Daten:
Die erfahrenen Programmierer unter uns bedienen sich diverser Programmiersprachen um auch mit großen oder sehr großen Datenmengen zu hantieren. Der gute alte SAS Data-Step (bzw. DS2 um innerhalb des Hadoop Clusters massiv parallel zu rechnen), Python oder auch Java tun hier gute Dienste.
Allerdings ist nicht jeder Data Scientist auch gleichzeitig ein erfahrener Programmierer und schreibt täglich Java, Python oder BASE SAS Code. Wer zum Beispiel mit Map/Reduce einfach nur die Worte in einem Text Dokument zählen will muss schon eine Menge tippen: http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html#Source+Code-N110D1 – ganz schön aufwendig!
Die gute Nachricht ist, das es auch einfacher geht! Wer mit SQL (bzw. HiveQL) zum Ziel kommt kann sehr viel Zeit einsparen. Im Falle von Hadoop kann man mit dem OpenSource Tool Hue schon sehr viel erreichen. Hue ist dabei eigentlich nur eine schicke Oberfläche für eine ganze Reihe von unterliegenden Hadoop Tools wie z.B. Hive, Scoop, dem Metastore, etc.
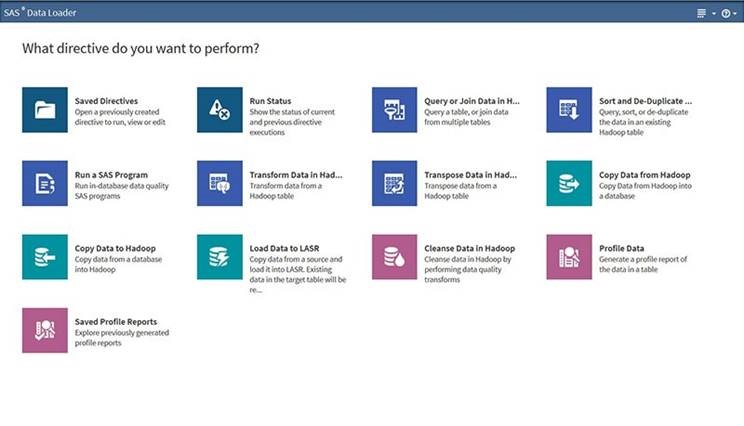
Wer es noch einfacher haben will und auch Datenqualitätsprobleme beheben will, der kann im Zusammenspiel mit Hadoop auch den neuen SAS Data Loader verwenden. Hier hat es viele “Easy Buttons” um die wichtigsten Tasks eines Data Scientisten im Zusammenhang mit der Datenaufbereitung abzudecken:
Folgende Aufgaben sollte das Tool der Wahl möglichst effizient abdecken:
Nach dem Hin-und-her schieben der Daten, dem Zusammenfügen von mehreren Datensätzen, dem Aufräumen und Säubern, kann man das Ergebnis dann in einem Tool der Wahl Explorieren und entweder nochmals durch den Daten-Aufbereitungsprozess iterieren (falls sich weitere Qualitätsprobleme zeigen oder Informationen fehlen) oder weiter zum zweiten Teil der Data Science – der “Science” gehen. Diesen Teil zu beschreiben überlasse ich aber lieber den Experten wie Dr. Diego Kuonen oder meinem Kollegen Carmelo Iantosca. Ich bin ja froh wenn ich Regression fehlerfrei schreiben kann ;)
Am Ende steht dann die Visualisierung. Dabei reichen die Optionen von der Kreuztabelle bis zum animierten Bubble-Chart. Stichwort hier ist “Agile Business Intelligence“.
Mehr Informationen und Anregungen zum Thema Data Science gibt es natürlich auch wieder auf den SAS Foren in der Schweiz (12. Mai) und Deutschland (9. Juni). Einen Persönlichkeitstest zum Thema Data Science gibt es hier: http://www.sas.de/ds.
Weitere Beiträge von SAS zum Thema Data Scientist finden Sie hier.
Vielfach hat die Coronapandemie bestehende IT-Strukturen aufgebrochen oder gar über den Haufen geworfen – gefühlt.…
Das Covid-Jahr 2020 konnte die digitale Transformation nicht ausbremsen. Sogar ganz im Gegenteil: Viele Unternehmen…
Nach Angaben der Weltbank fehlt mehr als einer Milliarde Menschen ein offizieller Identitätsnachweis. Ohne den…
Das Thema Nachhaltigkeit ist seit vielen Jahren fester Bestandteil des Selbstverständnisses vieler Unternehmen. Wenig verwunderlich,…
Unternehmen sammeln eine Vielzahl von Daten. Doch IDC Analysten fanden in ihrer aktuellen Studie „IDC‘s…
COVID-19 hat 2020 sowohl Gesellschaft als auch Wirtschaft bestimmt. Unbestritten ist auch die katalytische Wirkung,…